
AI agents perceive, reason, and act. The right architecture blends reactive speed with deliberative planning, adds learning and memory, and is instrumented for safety, evals, and observability.
Tyler Gibbs
Author
TL;DR: AI agents perceive, reason, and act. The "right" architecture blends reactive speed with deliberative planning, adds learning and memory, and is instrumented for safety, evals, and observability. This post surveys classic patterns (BDI, subsumption, blackboard), today's LLM-powered agent stacks, and pragmatic design checklists you can drop into production.
AI agents are autonomous systems designed to sense their environment, reason about it, and take actions toward specific goals. An agent's architecture is the blueprint that decides how it senses, how it thinks, and how it acts—plus how it learns from the outcomes.
The architecture defines not just the agent's capabilities but its limitations, failure modes, and production readiness. A well-designed architecture makes exciting failures hard to reach.
Every AI agent, regardless of complexity, comprises five fundamental components:
Perception Module → gathers state via sensors, APIs, RAG pipelines, or computer-use / browser tools. Normalization and schema alignment happen here. This is where the agent builds its understanding of the world.
Knowledge Base → stores structured facts (KBs, graphs), unstructured corpora, and vector embeddings. Split memory into episodic (events), semantic (facts), and procedural (skills/tools). The difference between a reactive bot and an intelligent agent often lies in the quality of its knowledge base.
Reasoning Engine → plans, predicts outcomes, and chooses actions. Mix symbolic planners (PDDL, rule engines), search (MCTS), and LLM reasoning patterns (CoT, ReAct, ToT, Reflexion). This is the "brain" where decisions get made.
Action Module → executes API calls, tool use, code, or robotic actuation. Encapsulate every action as an idempotent, auditable tool with strict schemas. Without reliable actions, even perfect reasoning is useless.
Learning Module → updates policies/knowledge from feedback (RL, bandits, distillation), self-critique traces, human review, or offline eval loops. This is what separates static systems from adaptive agents.
Tip: Treat the agent like a microservice with a contract: inputs (observations & goals), outputs (actions & artifacts), and SLAs (latency, reliability, guardrails).
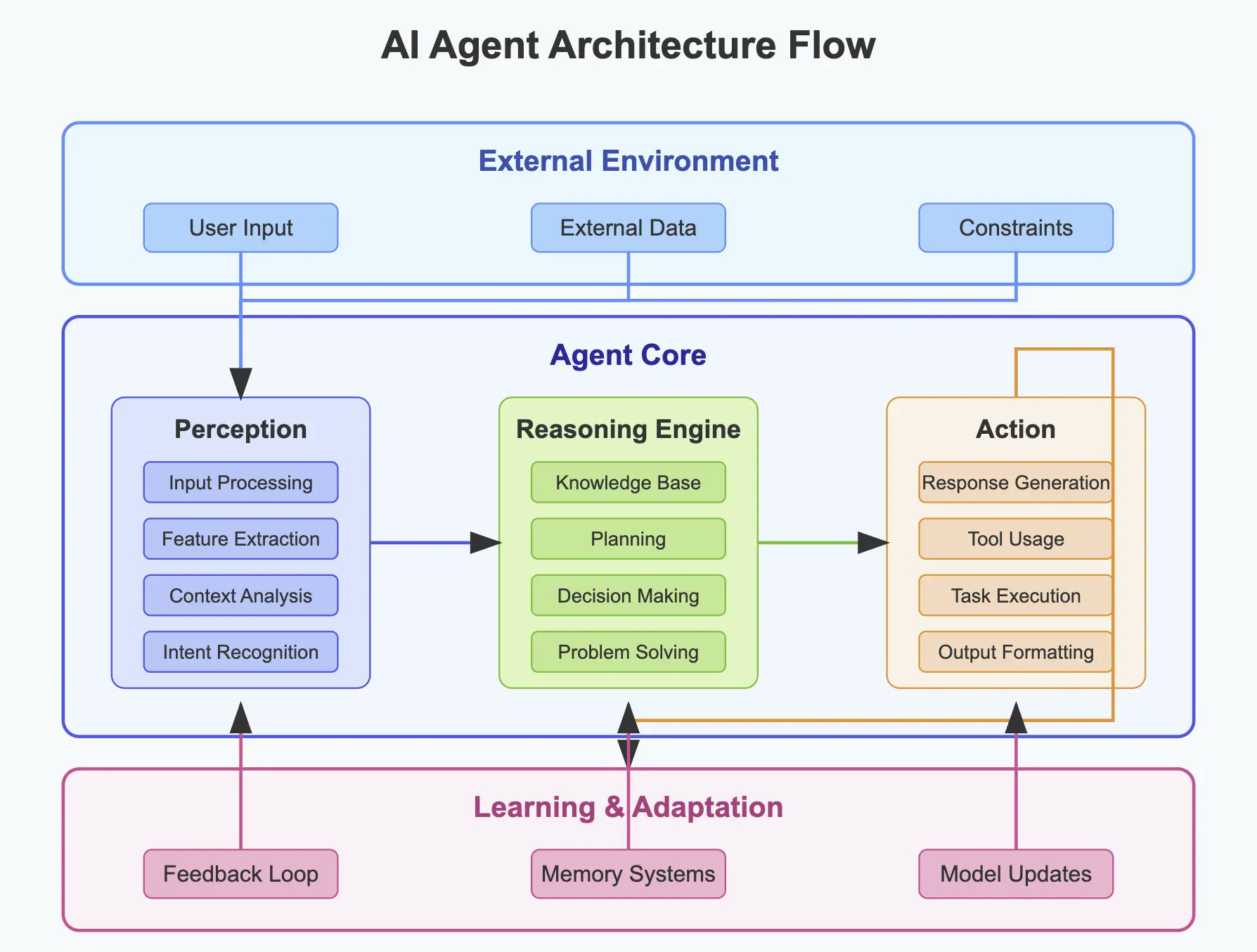 A complete agent workflow showing how perception feeds the knowledge base, the reasoning engine queries knowledge and selects actions, the action module executes decisions, and the learning module captures feedback to improve future performance.
A complete agent workflow showing how perception feeds the knowledge base, the reasoning engine queries knowledge and selects actions, the action module executes decisions, and the learning module captures feedback to improve future performance.
Direct stimulus → action. No explicit world model.
Pros: ultra-fast, robust on noisy sensors, low memory. Cons: limited foresight; brittle on long-horizon tasks. Examples: behavior-based robotics; event-triggered chatbots; production "computer-use" macro agents.
Reactive architectures excel when the environment is predictable and response time matters more than planning depth. They're the reflex system of AI.
Maintain internal state/world models; plan over them symbolically.
Pros: explainable plans; better at constraints. Cons: compute-heavy; model drift vs. reality. Examples: expert systems, classical planners, goal-directed assistants.
These systems think before they act. They're slower but handle complex, multi-step tasks where reactive approaches fail.
Layered designs: reactive skills on the bottom, planners on the top.
Pros: real-time safety and long-horizon competence. Cons: arbitration complexity; state synchronization. Examples: autonomous robots/vehicles; orchestration graphs with interrupts.
This is where theory meets practice. Most production systems are hybrid because they need both fast reflexes and strategic planning.
Behaviors learned from data (SL/UL/RL); improve with experience.
Pros: adaptable; can exceed hand-coded rules. Cons: data hunger, eval drift, explainability. Examples: RL agents (games, trading), tool-use LLM agents fine-tuned on trajectories.
Reality check: Most production systems are hybrid-learning: a reactive safety layer, a planner, and one or more learned policies.
BDI (Belief-Desire-Intention) → human-like goals and plans. Pair well with operations constraints (e.g., SLAs, budgets). Great for multi-goal arbitration. If your agent needs to juggle competing objectives, BDI gives you a principled framework.
Layered / Three-Tier → perception → reasoning → action with clean interfaces and back-pressure. Simple, debuggable, and scalable.
Blackboard → shared, structured "board" where specialist modules post hypotheses/results. Good for complex, multi-modal fusion. Think of it as a collaborative workspace where different experts contribute.
Subsumption → stack simple behaviors; higher layers can suppress/override lower ones. Useful for safety envelopes and reflexes. Your agent's emergency brake lives here.
Agents rarely act alone. In multi-agent systems (MAS):
Message schemas: Use standardized message formats (performative + content + ontology). Without shared protocols, agents can't coordinate.
Coordination styles:
Topologies:
Safety: rate-limit cross-talk, audit messages, and enforce tool budgets. Multi-agent systems can amplify failures exponentially if not properly constrained.
Scalability → batch/tool parallelism; sharded memory; checkpointable long-running graphs. Can your agent handle 10x the load without rewriting?
Robustness → typed tool contracts; retries/circuit breakers; sandboxed code execution; fallbacks (baseline policies). Production agents fail gracefully, not catastrophically.
Adaptability → online learning signals; schema evolution; few-shot updates. The world changes; your agent should too.
Transparency → structured traces (thoughts, tools, decisions), lineage for every artifact, and "why" logs for actions. If you can't debug it, you can't trust it.
Safety & Compliance → risk registers, policy checks pre-/post-action, and red-teaming harnesses. Especially critical for defense and government applications.
Observability → per-edge latency, tool failure taxonomies, success criteria, and cost accounting. You can't improve what you don't measure.
Intelligent assistants → task routing, RAG, function/tool calls, calendar/CRM ops. The agents you interact with daily.
Autonomous systems → drones/AMRs, industrial arms, self-driving subcomponents. Where agent failures have physical consequences.
Finance → portfolio rebalancers; market-making policies with guardrails and human-in-the-loop approvals. High-frequency decisions with high-stakes outcomes.
Healthcare → triage copilots, coding/billing, care-pathway planners (with strict auditability and clinical oversight). Lives depend on getting this right.
Smart infrastructure → grid control, building optimization, logistics orchestration. Silent agents managing complex systems at scale.
Planner-Executor (ReAct)
LLM proposes a thought → picks a tool → observes → repeats. Add critique steps to reduce hallucinations. The workhorse pattern for LLM agents.
Tree-of-Thought (ToT) Orchestrator
Maintain multiple candidate plans; score/prune with voting or MCTS, then execute the best. When the stakes are high and you have time to think.
Reflexion Loop
After each episode, write self-critique to episodic memory; use it to bias the next attempt. Agents that learn from their mistakes.
LangGraph-style DAGs
Stateful graphs with typed edges (Observation, Plan, Action, Result). Supports long-running workflows, checkpoints, and human-approval nodes. Production-grade orchestration.
MAS (Crew-style) Role-based agents (Researcher, Critic, Builder, QA) coordinate via shared context and task delegation. Specialized agents working together.
 A production-grade AI agent architecture showing the eight essential layers: Gateway for auth and rate limiting, Orchestrator for workflow management, Memory for knowledge storage, Tools for external interactions, Reasoners for decision-making, Safety for guardrails, Telemetry for observability, and Human-in-the-Loop for critical approvals.
A production-grade AI agent architecture showing the eight essential layers: Gateway for auth and rate limiting, Orchestrator for workflow management, Memory for knowledge storage, Tools for external interactions, Reasoners for decision-making, Safety for guardrails, Telemetry for observability, and Human-in-the-Loop for critical approvals.
This is the minimum viable architecture for production agents. Skip components at your own risk.
Edge: perception, reflexes, safety envelope, short-horizon skills.
Cloud: planning, global memory, heavy models.
Sync: durable event bus; conflict-free replicated data structures (CRDTs) for memory notes.
When network reliability matters, split intelligence between edge and cloud. Edge handles real-time decisions, cloud handles strategic planning. For a deep dive into the unique challenges of edge deployment in defense environments, see our post on Edge AI for Defense.
KPIs, costs, SLOsDAG, MAS)JSON Schemas); add retries and idempotency keysTTL policyCopy this checklist. Every skipped item is a future production incident.
LangGraph → low-level, stateful DAGs for single/multi-agent workflows.
AutoGen → conversation-centric multi-agent programming with human-in-the-loop and code-exec patterns.
CrewAI → role-based multi-agent orchestration with delegation and shared context.
BDI stacks → Jason/JADE/LightJason for symbolic goal-plan agents and FIPA messaging.
Eval/observability → LangSmith, custom traces, agent benchmarks (WebArena, AgentBench) as regression suites.
Unbounded loops → enforce step/time/cost budgets and termination criteria. Agents without guardrails run forever.
Opaque memory → store why entries were written; version schemas; purge staleness. Memory without provenance is technical debt.
Tool sprawl → consolidate a tool registry with ownership, SLAs, and unit tests. Unmanaged tools become unmaintainable.
Eval mismatch → ensure evals mirror production tasks and error modes (timeouts, 403s, bad HTML, flaky APIs). Testing in ideal conditions proves nothing.
Over-centralized orchestrators → avoid singletons; prefer partitioned, replayable event logs. Single points of failure are just that.
LLM-native agents → deeper tool use, computer-use (GUI) skills, and long-context memory. Agents that can navigate interfaces like humans.
Multi-agent collaboration → specialization and role-play with verified handoffs; negotiation protocols. Teams of agents, not just single actors.
Responsible autonomy → explainability, sandboxed execution, and policy-as-code aligned to regulation. As agents gain autonomy, accountability becomes critical.
Edge-deployed agents → low-latency reflexes on devices (Jetson/TinyML) + cloud planning. Intelligence distributed across the network.
Building production AI agents for defense and government has taught us that the best agent systems are boringly reliable—because their architecture makes exciting failures hard to reach.
The difference between a demo and a deployed system comes down to:
At Grayhaven, we build AI agents that work in environments where traditional approaches fail. Our architectures prioritize reliability over novelty, observability over opacity, and production readiness over benchmark performance. For more on implementing deep, production-grade agent systems, read our post on Deep Agents.
Classics / Architectures
LLM-Agent Reasoning Patterns
Frameworks (2024–2025)
Benchmarks & Evals
Safety / Governance
Edge Agents
Build for insight, not intrigue. The most reliable agents are the ones that make failure states unreachable.
More insights on AI engineering and production systems

The first generation of agents felt like wind-up toys. Deep agents reason, pace themselves, and keep working until the job is done or the budget runs out—here's how to build one that actually works.

How space-based custody, battle-manager handoffs, and edge-constrained inference shape the AI stack for intercepting maneuvering hypersonics.

Why resource-constrained environments break every assumption about AI deployment, and what that teaches us about building systems that actually work.
We build AI systems for defense and government operations. Let's discuss your requirements.