
The first generation of agents felt like wind-up toys. Deep agents reason, pace themselves, and keep working until the job is done or the budget runs out—here's how to build one that actually works.
Tyler Gibbs
Author
The first generation of agents felt like wind-up toys. You gave them a tool, set them in a loop, and watched them bump into the same walls. They could call a function, but they did not hold a plan in their head, and they forgot what they learned after a few steps. Deep agents are the antidote. They reason, they pace themselves, and they keep working until the job is done or the budget runs out.
If you want a one-sentence definition: a deep agent is an LLM that can plan, decompose, and persist work across time, not just across tokens. That sounds fuzzy, so here is the more concrete version.
The best working examples in the wild converge on four parts.
A detailed system prompt. The prompts that power strong research or coding agents are long, explicit, and full of examples. You are not "over-prompting"; you are giving the model the operating manual it never got at pretrain time. Claude Code is a good example, with public write-ups and reproductions showing extensive instructions that steer tool use and behavior.1
A planning tool. This can be a literal to-do list tool that is a no-op except for logging. It scaffolds the agent's attention, keeps it on track, and gives you a way to intervene. The strongest coding agents visibly draft and adjust checklists as they work.1
Subagents. Deep agents call specialists. They hand off to a researcher, a coder, a tester, a red-team checker, each with its own prompt and tool budget. Subagents isolate context so the supervisor does not drown in its own history. Anthropic documents this pattern for Claude Code, and LangChain's Deep Agents make it a first-class primitive.2
A file system. Not a metaphorical one. A real working memory that outlives a single message and can hold notes, partial outputs, retrieved documents, and scratch work. Claude Code and Manus both lean on a workspace. LangGraph and the Deep Agents package expose a virtual file system and a store you can read and write during runs.1
Put together, the loop is still "think, act, observe", but with a spine. The plan lives in text. Tasks split. Work products accumulate in files. The agent is free to continue tomorrow because tomorrow has somewhere to start.
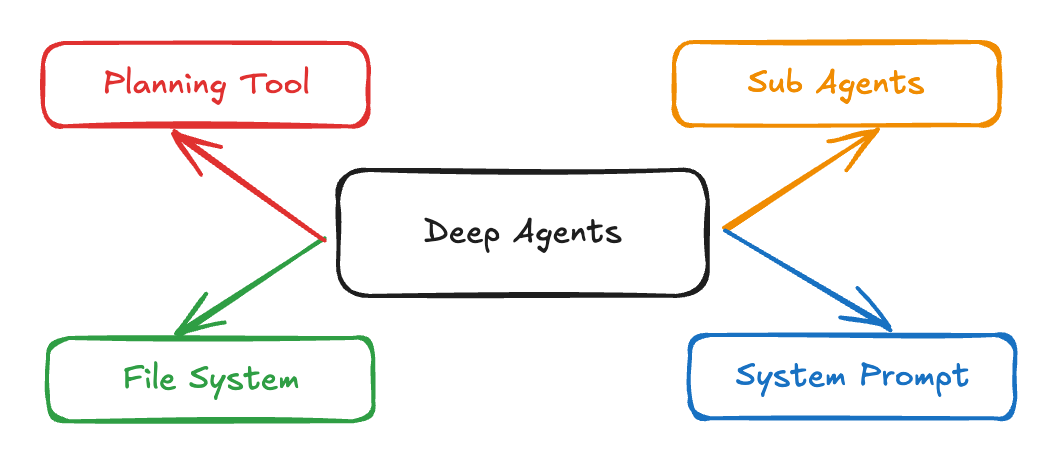 A deep agent architecture showing the four core ingredients: detailed system prompts that guide behavior, planning tools that scaffold attention and track progress, specialized subagents that handle specific tasks with isolated context, and a persistent file system that maintains state across sessions.
A deep agent architecture showing the four core ingredients: detailed system prompts that guide behavior, planning tools that scaffold attention and track progress, specialized subagents that handle specific tasks with isolated context, and a persistent file system that maintains state across sessions.
This year made the idea tangible. OpenAI shipped Deep Research inside ChatGPT. It plans a multi-step crawl, writes a report with citations, and shows its working. It is slow on purpose because it is doing actual work. The feature runs on their current reasoning stack and costs real compute, which is exactly what serious users asked for.3
In parallel the frameworks matured. LangGraph hit a stable 1.0 aimed at long-running, production agents. It treats agents like durable systems, not chatbots with tools. That matters when jobs take hours, involve many files, and need pausing, resuming, and human interrupts.4
The result is a pattern that is no longer hypothetical. Research agents and coding agents are the two clearest wins, and they look almost identical under the hood: big prompt, visible plan, subagents for depth, and a file system for memory.1
Benchmarks have finally caught up to the ambition and, in the process, humbled it. OSWorld measures real computer use on real apps. Humans clear more than 70 percent. The best agent struggles to clear the teens. That is not a reason to give up. It is a reason to design for depth, recovery, and supervision.5
Web agents face similar cliffs. WebArena gives you realistic sites, long instructions, and plenty of chances to go off course. Success comes from scaffolding and specialized data, not just bigger models.6
Safety is the other half of reality. Agent-SafetyBench and sibling efforts evaluated popular agents and found none could clear 60 percent on safety across diverse interaction hazards. You cannot bolt guardrails on after the fact. Deep agents must include interrupt points, allow approvals for risky tools, and run with least privilege.7
Below is a blueprint that has shipped for me.
Pick a durable runtime. If you want maximal control and resumability, start with LangGraph 1.0. If you want a batteries-included multi-agent orchestrator, look at CrewAI or Microsoft's new Agent Framework, which folds AutoGen's patterns into an enterprise-grade runtime. If you need async multi-agent at scale with monitoring, AgentScope is worth a look. The point is not the logo. The point is that your runtime must support long tasks, state, and human interrupts.4
Write the operating manual. Start with a base system prompt that includes role, goals, failure modes, examples, and tool contracts. Then add a small custom section for your vertical. Resist the urge to "let the model figure it out". The best public agents are heavily prompted for a reason.1
Make planning explicit. Add a to-do tool that records and updates steps. Require the agent to update the plan on any major observation, failure, or new document. Display the plan to users so they can correct course early.1
Spawn specialists. Define subagents with their own prompts, tools, and budgets. Keep the supervisor's context lean. Use a research subagent for retrieval, a coder subagent for code edits, a tester subagent for verification, and a critic subagent for risk and source checks. LangChain's Deep Agents and Claude Code both demonstrate the pattern.8
Persist everything that matters. Give the agent a working directory. Store notes, intermediate outputs, and retrieved sources. Teach the agent to summarize long logs into structured files. Use the store to carry state across sessions. This also makes the system auditable, which is important once these agents touch money or regulated data.8
Wire in human-in-the-loop. Configure interrupt points for sensitive tools like shell, purchases, or network writes. Surface proposed actions in plain language. Require approvals for anything with external side effects. Deep Agents exposes this via an interrupt config, and similar hooks exist in other frameworks.8
Evaluate the whole loop. Do not benchmark only the model. Use end-to-end tasks from OSWorld, WebArena, or GAIA to measure planning and tool use. Track success, retries, money spent, tokens spent, and human touches. Add a safety bench run as a gate for deployment.5
Control costs. Deep agents are compute hungry because they iterate, search, and write. One lever is architectural. Use small language models for glue code and large ones for hard reasoning. There is now a literature arguing that SLMs are often the right default inside agentic systems for economy and latency.9
Make failure first class. Expect lost context, runaway tool calls, partial writes, stale plans, and wrong sources. Mitigate with budget guards, plan refreshes, file diffs, idempotent writes, and source scoring. Put the plan and the source graph in the UI where users can correct them.
The most common anti-pattern is a shallow loop dressed up with tools. If you do not give the agent a place to put its thinking, it will free associate and then forget. The second anti-pattern is context hoarding. Agents that try to keep everything in the window get slow, then blind. Write to disk and reread.
A third is invisible work. Users will not trust an opaque machine that spends twenty minutes in silence and returns a PDF. Show the plan, the hops, the sources, and the costs as they accrue. OpenAI's Deep Research is explicit about steps and citations, and that is a big reason why the feature is usable.3
Finally, do not overfit to toy evals. If your agent aces a static QA task and then deletes a production folder, you did not win. Use the safety benches, set tool scopes per subagent, and require approvals for destructive actions.7
The interesting part of deep agents is not autonomy for its own sake. It is the migration of software from compiled logic to live, textual procedures that the system can read, revise, and persist. Plans become first-class artifacts. Subagents become teams. Files become memory. The work looks less like calling a clever function and more like onboarding a junior engineer who reads everything, writes down a plan, and keeps at it until the job is done.
We are still early. The best agents are great at research and coding, which are domains that reward reading and writing. The gap on real computers and real websites is still wide. The safety work is only now catching up. The pattern is stable enough to build with, though. If you respect the ingredients and evaluate the whole loop, you can ship a deep agent today that is boring in the best way: it quietly gets things done.10
For a comprehensive guide to the architectural patterns underlying deep agents, see our post on AI Agent Architectures.
At Grayhaven, we build AI agents that work in environments where traditional approaches fail. If you're designing agentic systems for production, let's talk.
Anthropic. "Subagents". Claude Docs ↩
LangGraph 1.0 Release. LangChain Changelog ↩ ↩2 ↩3
OSWorld: Benchmarking Multimodal Agents. NeurIPS Papers ↩ ↩2
WebArena: A Realistic Web Environment. webarena.dev ↩
Agent-SafetyBench: Evaluating the Safety of LLM Agents. arXiv:2412.14470 ↩ ↩2
Small Language Models are the Future of Agentic AI. arXiv:2506.02153 ↩
OpenAI launches 'deep research' tool. The Guardian ↩
More insights on AI engineering and production systems

AI agents perceive, reason, and act. The right architecture blends reactive speed with deliberative planning, adds learning and memory, and is instrumented for safety, evals, and observability.

How space-based custody, battle-manager handoffs, and edge-constrained inference shape the AI stack for intercepting maneuvering hypersonics.

Why resource-constrained environments break every assumption about AI deployment, and what that teaches us about building systems that actually work.
We build AI systems for defense and government operations. Let's discuss your requirements.